Cuando empecé a trabajar con los sistemas automáticos de trading, una de las primeras tareas que me autoasigné fue el desarrollar una metodología de trabajo que me permitiese determinar, de forma cuantitativa y dentro de un cierto intervalo de confianza, si un determinado sistema tiene esperanza matemática positiva, además de identificar cual es la estrategia de gestión del riesgo que mejor se le ajusta, y el tamaño óptimo de las posiciones a abrir. Una vez desarrollada la metodología, me llevé la desagradable sorpresa de que no existía en el marcado ninguna herramienta lo suficientementemente potente como para poder poner en marcha mi nueva metodología.
A partí de ahí, y gracias a mi formación como ingeniero informático, me puse a desarrollar mi propia herramienta de análisis de sistemas de trading. Con el tiempo, la herramienta llegó a un nivel de madurez que me hizo plantearme la posibilidad de venderla como un producto comercial. Como emprendedor sabía que sólo tienen éxito aquellos productos que los clientes necesitan, quieren, y están dispuestos a pagar por ellos. Pero ¿cómo no iban a querer los traders una herramienta que dado un sistema te dice si es o no rentabe, y además te ayuda a maxizar el retorno mientras minimiza el riesgo? Pues no, eso no es lo que quieren los traders. Al menos no es lo que quieren los traders individuales, que es el mercado al que me dirigía.
Efectivamente, la gente lo que quiere es una "Máquina Mágica". Es decir, una maquinita que pulses un botón y automáticamente salga dinero, sin que sea necesario dedicarle tiempo ni esfuerzo. Eso es lo que me estaban demandando. Y cuando le explicaba que dicha máquina no existe, los potenciales clientes no lo entendían, o mejor dicho, no lo querían entender. Algunos incluso se enfadaban, y me decían que el problema era que no quería compartir mis secretos (pero oiga, ha visto usted que tenga un Mercedes aparcado en la puerta de mi casa).
Así que no tuve más remedio que cancelar la versión comercial de Entropycs. Desgraciadamente ser empresario es incompatible con ser trader, ya que ambas son profesiones a tiempo completo, y hay que optar por una u otra. En cualquier caso, sigo mejorando la plataforma para mi uso interno, y seguiré dando cuenta de mis avances en este blog.
sábado, 17 de agosto de 2013
martes, 30 de julio de 2013
Indicador Técnico: RSI
El Índice de Fuerza Relativa, o RSI (del inglés Relative Strength Index), es un oscilador diseñado para medir la velocidad con la que varían los precios. El indicador RSI oscila entre los valores 0 y 100 y se calcula de la siguiente manera:
Donde AG es la ganancia media (del inglés Average Gain), es decir, la media aritmética de las últimas N barras con resultados positivos (y donde N es el periodo de cálculo del indicador), y AL es la pérdida media (del inglés Average Loss), o la media artimética de las pérdidas de las últimas N barras.
Por ejemplo, un RSI calculado sobre 14 barras podría ser el siguiente:

Tradicionalmente se dice que tenemos un mercado en sobrecompra cuando el RSI es superior a 70, y un mercado en sobreventa cuando es inferior a 30. Por tanto, un sencillo sistema de trading podría ser abrir en corto cuando tenemos un mercado en sobrecompra, y abrir en largo cuando está en sobreventa.
En el paquete TTR de R el indicador RSI se calcularía de la siguiente forma:
RSI(price, n = 14, maType)
donde maType es el tipo de media móvil que queremos utilizar para el cálculo del RSI (simple, exponencial, ...). Por ejemplo, el RSI(14) se calcularía como:
data(ttrc)
price <- ttrc[,"Close"]
rsi <- RSI(price, n=14)
Como resultado la variable macd contendría algo similar a:
100
RSI = 100 - --------
1 + RS
RS = AG / AL
Donde AG es la ganancia media (del inglés Average Gain), es decir, la media aritmética de las últimas N barras con resultados positivos (y donde N es el periodo de cálculo del indicador), y AL es la pérdida media (del inglés Average Loss), o la media artimética de las pérdidas de las últimas N barras.
Por ejemplo, un RSI calculado sobre 14 barras podría ser el siguiente:

Tradicionalmente se dice que tenemos un mercado en sobrecompra cuando el RSI es superior a 70, y un mercado en sobreventa cuando es inferior a 30. Por tanto, un sencillo sistema de trading podría ser abrir en corto cuando tenemos un mercado en sobrecompra, y abrir en largo cuando está en sobreventa.
En el paquete TTR de R el indicador RSI se calcularía de la siguiente forma:
RSI(price, n = 14, maType)
donde maType es el tipo de media móvil que queremos utilizar para el cálculo del RSI (simple, exponencial, ...). Por ejemplo, el RSI(14) se calcularía como:
data(ttrc)
price <- ttrc[,"Close"]
rsi <- RSI(price, n=14)
Como resultado la variable macd contendría algo similar a:
67.21311 68.33130 68.90238 71.65472 74.12134 74.12134 75.12550 70.69429 ...
martes, 23 de julio de 2013
Bolsa, timos y estadística
Cuando estudiaba matemáticas, en la asignatura de probabilidad y estadística de primero solían poner como ejemplo un sencillo timo en bolsa. El engaño era el siguiente: seleccionamos un gran número de inversores en bolsa (por ejemplo 1024), a continuación a la mitad le enviamos el Lunes una carta donde le decimos que durante la semana la bolsa subirá, y a la otra mitad otra carta donde le decimos que la bolsa bajará; a la semana siguiente, a los 512 inversores para los que hemos acertado les enviamos otra carta, nuevamente a la mitad le decimos que la bolsa subirá y a la otra mitad que bajará; a la semana siguiente, volvemos a hacer lo mismo con los 256 inversores para los que ya hemos acertado dos veces en nuestro pronóstico; al cabo de varias semanas nos quedarán unos 16 inversores para los que siempre hemos acertado; llegados a este punto le enviamos una última carta donde nos presentamos, les decimos cualquier parrafada de lo buenos que son nuestros métidos de predicción, y les ponemos como ejemplo las 6 semanas consecutivas que hemos acertado, y les decimos que si quieren la previsión para la siguiente semana nos tienen que pagar mil euros. Evidentemente, es difícil que alguien caiga en el timo, pero si lo organizamos a gran escala, empezando con 65.536 inversores y parando con 1024, a poco que pique uno de cada diez, tenemos un negocio redondo.
Este timo, que parece tan obvio, es utilizado habitualmente, por ejemplo, por los bancos: si preguntamos en un banco por un fondo de inversión rentable, seguro que nos muestran cuatro o cinco que nunca han perdido dinero; el cómo lo hacen es muy simple, se trata de abrir muchos fondos e ir cerrando aquellos que entren en pérdidas, de tal manera que los que queden tienen una rentabilidad continuada. También es un método utilizado por los gurús de la bolsa, en este caso el método consiste en hacer muchas predicciones cada día, y al día siguiente sólo recordad aquellas en las que han acertado.
Pero también se utiliza, y esto no es tan evidente, para el caso de los robots, o expert advisors, de trading automático. Ya que existen miles de robots funcionando, por pura estadística, algunos de ellos debe necesariamente ser rentables. Los vendedores nos muestran la rentabilidad pasada de dichos robots, y nos repiten una y otra vez que no se trata de "backtesting" o de rentabilidades en cuentas demo, sino de rentabilidades en real, como garantía de la eficacia del robot. Pero al igual que pasaba con nuestro timador de las cartas, lo normal es que estos robots, tarde o temprano, acaben abandonando la lista de robots con rentabilidades sostenidas en el tiempo, momento en el cual serán sustituidos por otros.
El que un robot haya tendio una rentabilidad sostenible en el pasado no quiere decir absolutamente nada, y por tanto, no debemos jugarnos nuestro dinero con ellos. Si queréis comprar un robot, seleccionar hoy un grupo de robots prometedores, seguir sus rentabilidades durante un tiempo prudencial, por ejemplo un año (el tiempo requerido depende de la frecuencia de las inversiones), y después decidir la compra.
Este timo, que parece tan obvio, es utilizado habitualmente, por ejemplo, por los bancos: si preguntamos en un banco por un fondo de inversión rentable, seguro que nos muestran cuatro o cinco que nunca han perdido dinero; el cómo lo hacen es muy simple, se trata de abrir muchos fondos e ir cerrando aquellos que entren en pérdidas, de tal manera que los que queden tienen una rentabilidad continuada. También es un método utilizado por los gurús de la bolsa, en este caso el método consiste en hacer muchas predicciones cada día, y al día siguiente sólo recordad aquellas en las que han acertado.
Pero también se utiliza, y esto no es tan evidente, para el caso de los robots, o expert advisors, de trading automático. Ya que existen miles de robots funcionando, por pura estadística, algunos de ellos debe necesariamente ser rentables. Los vendedores nos muestran la rentabilidad pasada de dichos robots, y nos repiten una y otra vez que no se trata de "backtesting" o de rentabilidades en cuentas demo, sino de rentabilidades en real, como garantía de la eficacia del robot. Pero al igual que pasaba con nuestro timador de las cartas, lo normal es que estos robots, tarde o temprano, acaben abandonando la lista de robots con rentabilidades sostenidas en el tiempo, momento en el cual serán sustituidos por otros.
El que un robot haya tendio una rentabilidad sostenible en el pasado no quiere decir absolutamente nada, y por tanto, no debemos jugarnos nuestro dinero con ellos. Si queréis comprar un robot, seleccionar hoy un grupo de robots prometedores, seguir sus rentabilidades durante un tiempo prudencial, por ejemplo un año (el tiempo requerido depende de la frecuencia de las inversiones), y después decidir la compra.
lunes, 1 de julio de 2013
Indicador Técnico: MACD
El indicador técnico MACD, o Media Móvil Convergente/Divergente (del inglés Moving Average Convergence / Divergence) es un oscilador que se basa en la diferencia de dos medias móviles, una media móvil lenta, y una media móvil rápida. El MACD se desglosa en tres componentes:

El indicador MACD combina lo mejor de dos mundos: los indicadores de tendencia y los osciladores. Sin embargo, dado que el indicador no se encuentra acotado dentro de un rango predefinido, es difícil utilizarlo para detectar niveles de sobrecompra o sobreventa.
Un sistema sencillo basado en el indicador MACD podría ser el siguiente: cuando la Línea MACD cruza al alza a la Línea de Señal abrimos en largo, y cuando la Línea MACD cruza a la baja a la Línea de señal abrimos en corto.
En el paquete TTR de R el indicador MACD se calcularía de la siguiente forma:
MACD(x, nFast = 12, nSlow = 26, nSig = 9, maType)
donde maType es el tipo de media móvil que queremos utilizar para el cálculo del MACD (simple, exponencial, ...). Por ejemplo, el MACD(12, 26, 9) se calcularía como:
data(ttrc)
macd <- MACD( ttrc[,"Close"], 12, 26, 9, maType="EMA" )
Como resultado la variable macd contendría algo similar a:
- Línea MACD: media móvil rápida - media móvil lenta
- Línea de Señal: media móvil aplicada sobre la Línea MACD
- Histograma MACD: Línea MACD - Línea de Señal

El indicador MACD combina lo mejor de dos mundos: los indicadores de tendencia y los osciladores. Sin embargo, dado que el indicador no se encuentra acotado dentro de un rango predefinido, es difícil utilizarlo para detectar niveles de sobrecompra o sobreventa.
Un sistema sencillo basado en el indicador MACD podría ser el siguiente: cuando la Línea MACD cruza al alza a la Línea de Señal abrimos en largo, y cuando la Línea MACD cruza a la baja a la Línea de señal abrimos en corto.
En el paquete TTR de R el indicador MACD se calcularía de la siguiente forma:
MACD(x, nFast = 12, nSlow = 26, nSig = 9, maType)
donde maType es el tipo de media móvil que queremos utilizar para el cálculo del MACD (simple, exponencial, ...). Por ejemplo, el MACD(12, 26, 9) se calcularía como:
data(ttrc)
macd <- MACD( ttrc[,"Close"], 12, 26, 9, maType="EMA" )
Como resultado la variable macd contendría algo similar a:
macd signal [1,] 1.6680643 2.1294258 [2,] 1.6230876 2.0281582 [3,] 1.6606279 1.9546521 [4,] 1.5104438 1.8658105 [5,] 1.3984768 1.7723437
sábado, 15 de junio de 2013
Indicador Técnico: Rango Verdadero Medio
El Rango Verdadero Medio, o ATR (del inglés Average True Range), es un indicador técnico que mide la volatilidad de un símbolo. El ATR se basa en los rangos (diferencia entre los precios máximo y mínimo) de las velas, con algunas modificaciones para tener en cuenta la existencia de huecos. Definimos el rango verdadero como:
rango_verdadero = máx[(máximo-mínimo), abs(máximo-cierre_prev), abs(mínimo-cierre_prev)]
Y a continuación, el rango medio de las útimas N barras es la media simple, o exponencial, de los últimos N rangos verdaderos.
Por ejemplo, un ATR de 14 barras sería el sigiente:
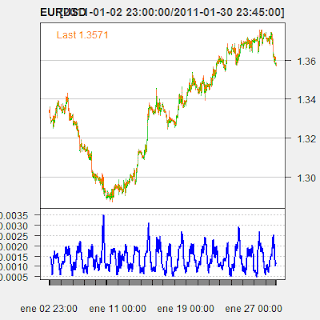
Generalmente, el ATR no se utiliza por sí mismo con un criterio de apertura en un sistema, en lugar de eso, se suele utilizar en combinación con otros indicadores técnicos, o simplemente como un filtro de órdenes. Por ejemplo, podemos crear un sistema basado en el cruce de dos medias móviles, y utilizar el indicador ATR para situar nuestros niveles de stop loss: si el símbolo va más allá de N veces el ATR en la dirección contraria a nuestra orden, podríamos decir que el movimiento no puede explicarse por las fluctuaciones debidas al ruido del mercado, sino que seguramente se trate de un cambio de tendencia, y por tanto, deberíamos cerrar la orden.
En el lenguaje Entropys el ATR se calcula como:
ATR(VECTOR, n)
Donde VECTOR es una serie temporal de precios, como por ejemplo aquella dada por la variable del sistema SYMBOL, y n es la longitud utilizada para calcular el ATR.
Para calcular un ATR de longitud 14 sobre el símbolo actual utilizaríamos algo como:
ind <- ATR(SYMBOL, 14)
Como resultado, la variable ind contendría algo similar a lo siguiente:
tr atr trueHigh trueLow
2011-01-03 03:30:00 0.0000 0.0004642857 1.3283 1.3283
2011-01-03 03:45:00 0.0006 0.0004739796 1.3282 1.3276
2011-01-03 04:00:00 0.0002 0.0004544096 1.3282 1.3280
2011-01-03 04:15:00 0.0009 0.0004862375 1.3291 1.3282
rango_verdadero = máx[(máximo-mínimo), abs(máximo-cierre_prev), abs(mínimo-cierre_prev)]
Y a continuación, el rango medio de las útimas N barras es la media simple, o exponencial, de los últimos N rangos verdaderos.
Por ejemplo, un ATR de 14 barras sería el sigiente:

Generalmente, el ATR no se utiliza por sí mismo con un criterio de apertura en un sistema, en lugar de eso, se suele utilizar en combinación con otros indicadores técnicos, o simplemente como un filtro de órdenes. Por ejemplo, podemos crear un sistema basado en el cruce de dos medias móviles, y utilizar el indicador ATR para situar nuestros niveles de stop loss: si el símbolo va más allá de N veces el ATR en la dirección contraria a nuestra orden, podríamos decir que el movimiento no puede explicarse por las fluctuaciones debidas al ruido del mercado, sino que seguramente se trate de un cambio de tendencia, y por tanto, deberíamos cerrar la orden.
En el lenguaje Entropys el ATR se calcula como:
ATR(VECTOR, n)
Donde VECTOR es una serie temporal de precios, como por ejemplo aquella dada por la variable del sistema SYMBOL, y n es la longitud utilizada para calcular el ATR.
Para calcular un ATR de longitud 14 sobre el símbolo actual utilizaríamos algo como:
ind <- ATR(SYMBOL, 14)
Como resultado, la variable ind contendría algo similar a lo siguiente:
tr atr trueHigh trueLow
2011-01-03 03:30:00 0.0000 0.0004642857 1.3283 1.3283
2011-01-03 03:45:00 0.0006 0.0004739796 1.3282 1.3276
2011-01-03 04:00:00 0.0002 0.0004544096 1.3282 1.3280
2011-01-03 04:15:00 0.0009 0.0004862375 1.3291 1.3282
sábado, 1 de junio de 2013
Programación Genética vs Gramáticas Evolutivas
Una de las principales problemas que se encuentran aquellos que descargan la plataforma Entropycs por primera vez es que el concepto de gramática evolutiva es difícil de entender. Y más concretamente, son muchos los que confunden las gramáticas evolutivas con la programación genética, y no es lo mismo. En esta entrada de blog intentaré explicar las diferencias entre ambas técnicas de optimización y búsqueda.
Quizás nos ayude a entender la diferencia si utilizamos el símil bioquímico de cómo se produce la evolución en la naturaleza. La información que nos permite "construir" un organismo vivo viene almacenada en una cadena de pares de bases denominada ADN, que a su vez se desliga en una cadena de ARN, que es interpretada generando secuencias de aminoácidos, que finalmente se convierten en las proteínas que son necesarias para el desarrollo de la vida. Cuando dos individuos se aparean, su descendencia herada una recombinación del ADN de los padres.
Tanto la programación genética como las gramaticas evolutivas se basan en mismo concepto de recombinación de la información de los padres; pero mientras las gramáticas evolutivas lo que recombinan son las cadenas de ADN (al igual que sucede en la naturaleza), la programación genética lo que recombina son las propias protenias finales. Traladado esto al mundo de la informática y de los lenguajes de programación, tenemos que las gramáticas evolutivas combinan cadenas de ADN que son interpretadas (por las gramáticas) para producir programas, y la programación genética lo que recombina son los propios programas.
En mi opinión, al añadir un nuevo nivel de abstracción introduciendo el concepto de gramática, se gana mucha flexibilidad, y se eliminan algunos de los principales problemas que nos encontramos con la programación genética.
Por ejemplo, las gramáticas evolutivas se basan en algoritmos genéticos para realizar la búsqueda de aquellos programas que mejor se adaptan a nuestras necesidades, pero nada nos impede utilizar otras técnicas de búsqueda, como son los enjambres de partículas, o evolución diferencial.
Por otro lado, con la programación genética el principal problema que nos encontramos es cómo garantizar que los programas que resultan de una recombinación son sintácitcamente correctos. Con las gramáticas evolutivas este problema simplemente desaparece, ya que la derivación de los programas, al estar basada en una gramática, por definición, son sintácticamente correctos.
Espero que con esta entrada haya quedado algo más clara la diferencia entre una optimización mediante gramáticas evolutivas y otra mediante programación genética.
Quizás nos ayude a entender la diferencia si utilizamos el símil bioquímico de cómo se produce la evolución en la naturaleza. La información que nos permite "construir" un organismo vivo viene almacenada en una cadena de pares de bases denominada ADN, que a su vez se desliga en una cadena de ARN, que es interpretada generando secuencias de aminoácidos, que finalmente se convierten en las proteínas que son necesarias para el desarrollo de la vida. Cuando dos individuos se aparean, su descendencia herada una recombinación del ADN de los padres.
Tanto la programación genética como las gramaticas evolutivas se basan en mismo concepto de recombinación de la información de los padres; pero mientras las gramáticas evolutivas lo que recombinan son las cadenas de ADN (al igual que sucede en la naturaleza), la programación genética lo que recombina son las propias protenias finales. Traladado esto al mundo de la informática y de los lenguajes de programación, tenemos que las gramáticas evolutivas combinan cadenas de ADN que son interpretadas (por las gramáticas) para producir programas, y la programación genética lo que recombina son los propios programas.
En mi opinión, al añadir un nuevo nivel de abstracción introduciendo el concepto de gramática, se gana mucha flexibilidad, y se eliminan algunos de los principales problemas que nos encontramos con la programación genética.
Por ejemplo, las gramáticas evolutivas se basan en algoritmos genéticos para realizar la búsqueda de aquellos programas que mejor se adaptan a nuestras necesidades, pero nada nos impede utilizar otras técnicas de búsqueda, como son los enjambres de partículas, o evolución diferencial.
Por otro lado, con la programación genética el principal problema que nos encontramos es cómo garantizar que los programas que resultan de una recombinación son sintácitcamente correctos. Con las gramáticas evolutivas este problema simplemente desaparece, ya que la derivación de los programas, al estar basada en una gramática, por definición, son sintácticamente correctos.
Espero que con esta entrada haya quedado algo más clara la diferencia entre una optimización mediante gramáticas evolutivas y otra mediante programación genética.
sábado, 25 de mayo de 2013
¿Cómo saber si un sistema es rentable? (3)
Seguimos con la tercera entrada de nuestra metodología de desarrollo y análisis de sistemas de trading.
Una vez se tenga claramente definida la estrategia a seguir (como vimos en nuestra entrada anterior), se deberá proceder a implementar la estrategia mediante alguno de los lenguajes de programación existentes en las distintas plataformas de trading. Este tarea se compone de dos pasos:
1.- Desarrollo
Durante la fase de desarrollo sólo se espera que el código compile y que genere señales de entrada y salida en el mercado aproximadamente correctas (pueden contener errores e imprecisiones), y que no den ningún tipo de mensajes de error. El código fuente debe seguir los estándares de calidad que hayan sido marcados (indentación, comentarios, etc), e idealmente debería estar basado en plantillas de desarrollo ya existentes.
Durante la fase de desarrollo sólo se espera que el código compile y que genere señales de entrada y salida en el mercado aproximadamente correctas (pueden contener errores e imprecisiones), y que no den ningún tipo de mensajes de error. El código fuente debe seguir los estándares de calidad que hayan sido marcados (indentación, comentarios, etc), e idealmente debería estar basado en plantillas de desarrollo ya existentes.
2.- Depuración
En este apartado se deberán comprobar las entradas y salidas individuales generadas por el sistema, así como los cálculos intermedios realizados. El objetivo es determinar si la implementación que se ha realizado de la estrategia es correcta. Para ello se deberá realizar una simulación histórica de la misma. El tamaño de la muestra para la simulación debe lo suficientemente grande para que se produzcan varias entradas en el mercado para cada una de las posibles combinaciones de reglas del sistema, filtros aplicables, gestión del riesgo y gestión monetaria. Durante la simulación se deberán utilizar valores “razonables” para los distintos parámetros de configuración, ya que en este paso lo importante es comprobar que las reglas funcionan correctamente, y no tanto evaluar la rentabilidad del sistema. A continuación se deberán analizar, barra a barra, las distintas entradas y salidas del mercado que se han producido, y comprobar que se ajustan a lo esperado.
Ejemplo: Cruce de dos Medias Móviles
Desarrollo
La estrategia ha sido programada mediante el lenguaje mql4 y la plataforma MetaTrader 4. El análisis de los datos ha sido realizado utilizando el lenguaje de programación R. Para los datos históricos, se utilizarán los datos en barras de 1 minuto proporcionados por el broker XTB, y que serán agrupados en barras de distintas longitudes (5m, 15m, 30m, etc).
Si alguien tiene interés en conseguir una copia del código, puede ponerse directamente en contacto conmigo y se la haré llegar por correo electrónico.
Depuración
Se ha comprobado el comportamiento correcto del sistema en los siguientes supuestos:
- Entradas en largo y en corto
- Re-entradas correctas después de una salida debido a un stop loss
Para las pruebas se ha utilizado una media móvil corta de 5 barras (una semana), una media móvil intermedia de 11 barras (medio mes), y una media móvil larga de 22 barras (aproximadamente un mes). El sistema se prueba sobre barras diarias para el símbolo EURUSD, durante los años 2010 y 2011. Nótese que cada vez que se ha encontrado un error, y se ha procedido a su corrección, la totalidad de los casos de prueba han sido repetidos (regression testing).
Los supuestos de prueba han sido articulados según los siguientes casos:
- Entradas en largo
- Entradas en corto
- Re-entrada después de SL
- Entrada incial
A modo de ejemplo, se muestran los resultados de las pruebas correspondientes al caso de entradas en largo:
Caso 1: Entrada en largo
El caso 1 se centra en la comprobación de las entradas en largo.
Objetivo: Comprobar que cuando la media móvil corta cruza al alza a la media larga se abre una nueva posición en largo, con el stop loss adecuado, y se cierra la posición en corto si la hubiera.
Resultado Esperado: Cierre y apertura de una nueva posición.
Resultado Obtenido: En el gráfico se puede observar que el cruce de la media móvil corta al alza sobre la media móvil larga se produce el 17/6/10. En este momento se cierra la posición que teníamos abierta en corto, y se abre una nueva posición en largo, con el correspondiente SL situado en la media móvil intermedia.
El caso 1 se centra en la comprobación de las entradas en largo.
Objetivo: Comprobar que cuando la media móvil corta cruza al alza a la media larga se abre una nueva posición en largo, con el stop loss adecuado, y se cierra la posición en corto si la hubiera.
Resultado Esperado: Cierre y apertura de una nueva posición.
Resultado Obtenido: En el gráfico se puede observar que el cruce de la media móvil corta al alza sobre la media móvil larga se produce el 17/6/10. En este momento se cierra la posición que teníamos abierta en corto, y se abre una nueva posición en largo, con el correspondiente SL situado en la media móvil intermedia.

Suscribirse a:
Entradas (Atom)